Statistics and Probability
Definition
Presentation of Statistical Data
Measure of Central Tendency
Probability
Complementary Events
Definition
Population and Sample
A population refers to the
entire set of data that we want to study. When we want to obtain reliable
information about the population, it is often impossible or impractical for us
to study the entire population as it may be too huge. Therefore, we need to
select a sample which is a representative subset
of the population.
To avoid any possible bias during sampling, we select a random sample such that any observations made are
independent.
Discrete Data
Discrete variables take on a countable number of possible
values and are often restricted to integer values. Examples include shoe sizes
and number of students in a class. When discrete data is presented in a
frequency table, it may be individual or grouped into classes.
Continuous Data
Continuous variables can take on any value in a certain
range and are usually not restricted to integer values. Examples include height
and weight. When continuous data is presented in a frequency distribution
table, the data is grouped into ranges.
Presentation of Statistical Data
Frequency Table
A frequency table shows the frequency of occurrence of each
element in a dataset.
Bar Chart
A bar chart is a diagram where discrete data is represented
by horizontal or vertical bars. The size of each bar represents the frequency
data.
Histogram
A histogram is a vertical bar chart representing numerical
information, often used for continuous data. The area of each rectangle is
proportional to its frequency. By using class boundaries instead of class
intervals, there will not be any gaps between the bars.
Grouped Data
Class limits may be used to represent a certain class
interval. However, to avoid any ambiguity, a class interval such as 50 to 59 will
be taken as 49.5 to 59.5. In this example, the class width is 10 units.
Measure of Central Tendency
Mean
The mean is the sum of the observations divided by the total
number of observations in a set. To calculate the mean of grouped data, we
represent all values in a class interval by the middle value of the interval.
Population mean,
Median
The median is the middle observation (for the case of an odd
number of observations) or the mean of two middle observations (for the case of
an even number of observations) when the set is arranged in ascending order.
Lower Quartile
The median divides the set into two halves. The median of
the set of the lower values is known as the lower quartile.
Upper Quartile
The median of the set of higher values in a set divided into
two halves is known as the upper quartile.
Interquartile
Range
The interquartile range refers to the difference in value
between the upper quartile and lower quartile.

Percentile
Similarly, a set of values can be divided into 100 equal
parts. Each of the parts is called a percentile. The median corresponds to the
50th percentile. The lower quartile corresponds to the 25th percentile, while
the upper quartile corresponds to the 75th percentile.
Mode
The mode refers to the observation which has the highest
number of occurrences in a set. In a grouped frequency distribution, the class
with the highest number of occurrences is known as the modal
class.
Variance
The population variance is an indicator of how spread out
the observations is from the average.
Population variance,
Standard Deviation
The sample standard deviation is the square root of the
sample variance.
When data is given in the form of a frequency distribution,
the standard deviation is given by
.
Probability
In a given possibility space (the set of all possible
outcomes) U, each possible outcome is known as a
sample point. If the possibility space has a finite number of sample points,
the number of points is denoted by n(U).
For an event A which has m sample points, and that there are n sample points in the possibility space, the
probability .
In other words, for an event A which can happen m out of n equally likely
outcomes (i.e. there is no bias), the probability of it happening is denoted by
P(A).
Since A is a subset of U, we have ,
which can be simplified to .
In other words, .
Complementary Events
The complement of an event A
refers to the event that A does not occur, and is
usually denoted as .
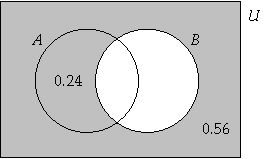
Venn Diagram
We may use a Venn diagram to illustrate the relationship
between the probabilities of two events, A and B.

From the Venn diagram, we can observe this relationship:
,
where and ,
which is also written as .
Conditional Probability
Given two events A and B such that and ,
the probability of A, given that B has already occurred is
.
Mutually Exclusive Events
Two events A and B are mutually exclusive if the probability of both
events occurring at the same time is zero. In other words, both events A and B cannot occur
together.
Exhaustive Events
Two events A and B are exhaustive if the probability of either event
occurring is 1.
The complementary events A and are mutually exclusive and exhaustive.
Independent Events
Two events A and B are independent if the occurrence of A does not affect the occurrence of B.
When given two independent events, we notice that the probability
of each event remains constant, regardless of whether the other event has
occurred.
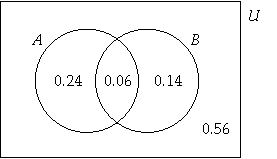
Consider and ,
which gives us and .
.
We can find the other values based on the given information.
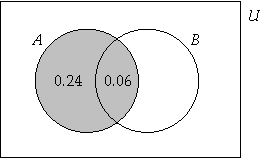
When we consider that A has
occurred, the probability of B occurring and the
probability of B not occurring remains the same.
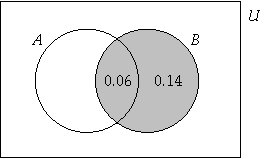
When we consider that B has
occurred, the probability of A occurring and the
probability of A not occurring remains the same.
When we consider that A has not
occurred, the probability of B occurring and the
probability of B not occurring remains the same.

When we consider that B has not
occurred, the probability of A occurring and the
probability of A not occurring remains the same.
From the above cases, we observe that the probability of an
event occurring or not occurring is not affected by that of the other event.
Bayes' Theorem
Three Events
The above results can be extended to three events.
Tree Diagram
A tree diagram can be used to determine the probability of
obtaining specific results. In the tree diagram below, the probability of
picking one red ball and one blue ball without replacement is .

Random Variables
A variable describes a quantity being measured. When this
variable comes from a random experiment, it is known as a random variable.
Random variables are often denoted by capital letters such as X, while the possible values for the random variables
are denoted by small letters such as x.
Discrete Random Variables
Discrete random variables take on a countable number of
possible values and are often restricted to integer values.
For a discrete variable which can assume a countable number
of values ,
the probabilities associated must be such that .
0 is excluded because will not be included in the list of values
when it cannot occur.
Probability Density Function
The probability distribution of a discrete random variable
shows the possible values of X and their
associated probabilities. The probability distribution can be presented either
in a table form or in a graphical form.
The probability density function (PDF) gives the
relationship between the possible values of X and
their associated probabilities. It is often expressed as a formula depending on
the type of distribution.
Cumulative Distribution Function
The cumulative distribution function (CDF) gives the sum of
the associated probabilities for the possible values of X
up to a certain value not more than x.
Suppose that X can assume
integer values between 0 and 6 inclusive.
Expectation
The expectation of a discrete random variable X is defined by
.
Numerically, the expectation is equal to the population
mean, μ.
If E(X) is the expectation of X,
E(k) = k, where k is a constant,
E(kX) = kE(X), where k is a constant,
,
where a and b are
constants.
Variance
The population variance is defined by
For the case of a discrete random variable X,
.
The population standard deviation of the discrete random
variable X is .
If Var(X) is the variance of X,
Var(k) = 0, where k is a constant,
Var(kX) = ,
where k is a constant,
,
where a and b are
constants.
We must add two variances because variance is always
positive.
Binomial Distribution
In an experiment with n
repeated independent trials and two mutually exclusive outcomes, where either
success or failure can occur, we will obtain a binomial distribution. It is
necessary for the probability of success p to
remain the same throughout the experiment.
When X follows a binomial distribution,
we say that ,
where there is a total of n trials and the
probability of success is p.
,
where
Poisson Distribution
The Poisson distribution is often used to model the
probability of a number of events occurring in a fixed period of time, with a
known mean value.
When X follows a Poisson
distribution, we say that ,
where m is the parameter such that m > 0. Observe that there is no upper limit for x.
,
where
Poisson Approximation to the Binomial Distribution
A binomial distribution can be approximated using the
Poisson distribution with mean m = np when
n is large (n > 50), and
p is sufficiently small such that np
< 5.
Continuous Random Variables
Continuous random variables can take on any value on the
number line. A continuous probability density function (PDF) is a function where
,
on a given interval.
The expectation for a continuous random variable is
,
while the variance for a continuous random variable is
.
Normal Distribution
When a continuous random variable X
follows a normal distribution, we say that .
The probability density function ,
where .
The area under the probability density function gives us the probabilities. For
all values of x, and .
To find ,
we may use the GDC as the above function is difficult to integrate.
The normal distribution is bell-shaped and symmetrical about
the line x = μ. The
maximum value of f(x)
occurs at x = μ,
where at that point. There are two points of
inflexion at .
Standard Normal Distribution
When μ and are unknown, we need to standardise the
variable such that and .
This distribution is known as the standard normal distribution, where .
We can also make use of the symmetrical properties of the
curve when finding positive and negative values of z.
To find the value of x given
the value of p such that P(X
< x) = p, we may
use the inverse normal function.
